This post is part of a series of AWS related posts.
Intro
This post documents my AWS SAP exam preparation and everything that comes with it. My strategy was simple. I’ve started the learning process by taking a Udemy course. The course was rather lengthy, so I didn’t repeat the course material 🤓. Instead, I completed practice exams and took note of everything I either forgot or didn’t know in the first place. Thus, the notes below are a mix of course repetition and complementary information.
The AWS Solution Architect Professional (SAP-C01) exam focuses on the same topics as the SAA exam. However, it is a bit more in-depth and Enterprise solution architectures are given a lot more weight. According to AWS, hands-on experience is required for this exam. 💡 You can compensate for missing field experience by learning about common solution architectures.
Learning Strategy
To prepare for the exam, I deployed the following learning strategy:
- Watch entire Udemy course
- Repeat failed questions in course quizzes
- Do practice exams
- solve example questions from the AWS exam page
- buy & solve question sets on Udemy (I completed 2 out of 5 practice exams)
- Take the exam (good luck! 🤞)
Notes
The notes below are structured using the same titles as in the Udemy course. Since the course has
evolved to cover SAP-C02, some titles might no longer match.
Section 3: Identity & Federation
- NotAction (“Deny everything except …”)
- default IAM permissions are implicit deny
- implicit deny can be overridden by explicit allow
- explicit deny cannot be override by explicit allow
- hence, if an action
iam:*is set to deny, a subset cannot be whitelisted. if that’s required, useallow NotAction iam:*, then allow subset, e.g “allow actioniam:ListUsers”- –>
NotActiondeny can be overridden by explicit allow
- –>
- Permission Boundaries: maximum permissions that an identity-based policy can grant to an IAM entity
- IAM Access Analyzer: shows which resources are exposed to external entities in your organization & accounts
- IAM policies vs. resource policies
- IAM policies permissions are applied when a role is assumed
- assuming a role means dropping all other permissions
- a role applies only to one AWS account, therefore accessing resources in another account
cannot be done by assuming a role from the requesting account.
Instead, you have two options:
- the target resource in destination account has an in-line, trust policy allowing (with constraints) the principal from source
account access
- a principal does not have to give up any permissions when using a resource-based policy
- the source principal (user or role) assumes a role in the target account
- the target resource in destination account has an in-line, trust policy allowing (with constraints) the principal from source
account access
- IAM trust policy:
- A policy in which you define the principals that you trust to assume the role
- To assume a role, an entity must have the IAM policy permissions to assume said role AND the role’s trust policy must allow it as well
- A role trust policy is a resource-based policy that is attached to a role in IAM
AWS Organization
AWS Resource Access Manager (RAM)
AWS Resource Access Manager (AWS RAM) enables to share AWS resources with other AWS accounts.
To enable trusted access with AWS Organizations:
- AWS RAM CLI: use the
enable-sharing-with-aws-organizationscommand - This trusted access enables an AWS service, called the trusted service, to perform tasks in your organization and its accounts on your behalf.
- this means the service is allowed to create IAM service accounts in all target AWS accounts or AWS organization that it can then assume and execute
- it cannot give itself more permissions than declared in the service description
- AWS RAM CLI: use the
Custom IdP
- AWS supports identity federation with SAML 2.0 -> whenever federated access to AWS resources is required, use SAML for authorization (e.g. in combination with arbitrary protocol, such as LDAP, for authentication)
Scenario: Architect has created a SAML 2.0 based federated identity solution that integrates with the company IdP, things to do:
- Include the ARN of the SAML provider, the ARN of the IAM role,
and SAML assertion from the IdP when the federated identity
web portal calls the AWS STS
AssumeRoleWithSAMLAPI - Ensure that the trust policy of the IAM roles created for the federated users or groups has the SAML-based custom IdP as principal set
- Ensure that the IAM roles are mapped to company users and groups in the IdP’s SAML assertions
Section 4: Security
Identity Management
AWS Cognito
- Amazon Cognito is used for single sign-on in mobile and web applications.
- You don’t have to use it if you already have an existing Directory Service to be used for authentication (then opt for a directory service connector)
AWS Config
- AWS Config simply enables to assess, audit, and evaluate the configurations of your AWS resources (no management capabilities!)
AWS Control Tower
- set up and govern multi-account AWS environment, called a landing zone
- orchestrates the capabilities of several other AWS services, including AWS Organizations, AWS Service Catalog, and AWS IAM Identity Center (successor to AWS SSO), SCPs
Section 5: Compute & Load Balancing
EC2 Instances
- Costs: On-Demand > Reserved Instances (RI) > Spot Instances
- Setting up a diversified allocation strategy for your Spot Fleet is a best practice to increase the chances that a spot request can be fulfilled by EC2 capacity
- Use spot instances for async processing of workloads, but not to host a consistent service
API Gateway
- API gateways can consume Kinesis data streams using the websockets protocol
- As a backend service to communicate with a client on “the other side” of the
API gateway, use the
@connectionsAPI
Section 6: Storage
AWS Storage Gateway
- Authentication mechanism per protocol
- iSCSI: CHAP authentication
- NFS: IP address-based filtering
- SMB: MS AD authentication
Stored Volume Gateway
- Stored Volume Gateway can provide cloud-backed storage volumes that can be mounted as iSCSI devices from on-premises systems
- Stored volumes, store your primary data locally, while asynchronously backing up that data to AWS S3
- Up to 512 TB of storage
Cached Volume Gateway
- Cached volume gateways provide low-latency access to frequently accessed data but not to the entire data
- Up to 1024 TB of storage
File Storage Gateway
S3 File Gateway:
- A file gateway that enables to store and retrieve objects in S3 using NFS and SMB - high-latency data access
- NFS, CIFS/SMB, other NAS filesystems, HDFS (Hadoop) are not POSIX compatible
FSx File Gateway:
- provides low-latency, on-premises access to fully managed file shares in Amazon FSx for Windows File Server
EBS
- EBS volumes support live configuration changes while in production which means that you can modify the volume type, volume size, and IOPS capacity without service interruptions
- EBS encryption uses 256-bit Advanced Encryption Standard (AES)
- An EBS volume in an AZ is automatically replicated within that zone to protect from data loss due to single HW component failure
S3
- Static web hosting
- Bucket name must be the same as domain or subdomain name. E.g.
for subdomain
foobar.p15r.net, the bucket name must befoobar.p15r.net
- Bucket name must be the same as domain or subdomain name. E.g.
for subdomain
- AWS Datasync & AWS Storage Gateway can sync on-prem data directly into AWS Glacier Deep Archive (while other services first sync to S3 standard tier, then use lifecycle policy to transfer data to other tiers after 30d)
- S3 Transfer Acceleration enables fast transfers of files over long distances to and from (!!) clients and S3 bucket. Transfer Acceleration uses CloudFront’s global edge locations. Use it to upload to buckets in other regions than the client.
Versioning
- If the Versioning feature is enabled after files have already been written,
all of the existing files will have a Version ID of
null - for any file uploaded after Versioning has been enabled, they will have an alphanumeric VERSION ID from first version onwards
Section 8: Databases
- Read-replicas have eventual read consistency
- For strict read-after-write consistency, read from master database
- AWS RDS has no (reader/writer) endpoints - only Aurora has
- RDS does not support Oracle enterprise features, such as Multitenant Database,
Real Application Clusters (RAC), Unified Auditing, Database Vault, and more
- install Oracle yourself on EC2 instance if a certain feature is required
Multi-AZ vs Read-Replicas
- RDS Read-Replicas improve performance and because they can be promoted to master, they improve durability as well (thus also high-availability)
- RDS multi-az means that in one AZ is master and in another zone are stand-by systems, thus only HA is improved, performance is not
RDS Proxy
- An RDS Proxy is installed between application and database
- Many applications, including serverless apps, can have a large number of open connections to the database server and may open and close database connections at a high rate, exhausting database memory and compute resources. RDS Proxy allows applications to pool and share connections established with the database, improving database efficiency and application scalability
DynamoDB
- Global Tables is a feature on top of DynamoDB’s global footprint to provide a fully managed, multi-region, and multi-master database
- Global Tables provides fast, local, read and write performance for massively scaled, global applications
- Global Tables replicates your DynamoDB tables automatically across your selection of AWS regions
- DynamoDB Global Tables is the only multi-master, multi-region DB! (Amazon Aurora multi-master works only within one region)
Oracle
- RAC: real application cluster; the most advanced Oracle tech providing
highly available and scalable relational databases.
It allows multiple Oracle instances to access a single database
- Amazon RDS (& Aurora) do NOT support Oracle RAC
- RMAN: Oracle Recovery Manager (RMAN) is not supported on RDS, because it
requires shell access. However,
rdsadmin.rdsadmin_rman_utilprovides RMAN tasks to create Oracle RMAN backups of RDS Oracle database and store it on disk. - To export on-prem Oracle database and restore to AWS RDS for Oracle:
- use AWS DMS
- use native Oracle export & import utility
Section 9: Service Communication
SQS
- Messages in SQS queues cannot be prioritized - create separate queues if prioritization is needed and implement prio. logic in consumers
Section 12: Deployment & Instance Management
AWS Systems Manager (SSM)
Patch Baselines
Patch baselines install security & bug fixes (Windows “CriticalUpdates” or “SecurityUpdates”):
AWS-FLAVORDefaultPatchBaseline- baseline for FLAVOR (e.g. CentOS)AWS-DefaultPatchBaseline- baseline for Windows- alias:
AWS-WindowsPredefinedPatchBaseline-OS
- alias:
Use the SSM Patch Manager AWS-RunPatchBaseline document (think of an Ansible
playbook) to apply the baselines. When using this document, there is no need
to use the SSM Run command to execute the baselines. SSM Agent is required.
Create two Patch Groups with unique tags to patch multiple instances at
different times, thus ensuring availability of your system (tags are
resource tags, e.g. env=prod, env=staging).
Define Rate Control (concurrency & error threshold) for the task.
Section 14: Migration
Disaster Recovery
Schema Conversion Tool (SCT)
- AWS SCT is not used for data replication; it eases up the conversion of source databases to a format compatible with the target database while MIGRATING
Data Migration Service (DMS)
- AWS DMS and its task
full load and change data capture (CDC)for continuous REPLICATION - when providing, for example, a MySQL endpoint for on-prem systems to send data for replication to cloud, a CA authority and SSL cert must be configured
Section X: Networking
VPC
- A VPC can operate in dual-stack mode — your resources can communicate over IPv4, or IPv6, or both. IPv4 and IPv6 communication are independent of each other. You cannot disable IPv4 support for your VPC and subnets since this is the default IP addressing system for Amazon VPC and Amazon EC2.
Direct Connection
- Private virtual interface: should be used to access an Amazon VPC using private IP addresses.
- Public virtual interface: can access all AWS public services using public IP addresses.
To connect to services, such as EC2, using Direct Connect a, private virtual interface is required. If you want to encrypt the traffic going through Direct Connect, you can use a VPN connection which, however, requires you to use a public virtual interface. This will then allow access to any AWS services.
ALB
- ALB does not support TCP/UDP health checks, only L7 (http and https)
- ALBs cannot be assigned elastic IPs, if static IP address is required for a load balancer, switch to a network load balancer
NLB
The NLB itself doesn’t have any security groups. Instead, you control access using the security groups(s) attached to the EC2 instances. The source IP address is preserved (NLB is transparent), so you work with security group configuration (and other firewalls so to speak) as if the client had connected directly to your machine.
Route53 DNS
enableDnsHostnames: Determines whether the VPC supports assigning public DNS hostnames to instances with public IP addresses.enableDnsSupport: Determines whether the VPC supports DNS resolution through the Amazon provided DNS server.- Private DNS zone sharing:
- Option 1 (simple):
- Assume Account 1 has the private zone dns configured
- Account 1: create an association authorization to link its private hosted zone to the VPC in Account 2
- Account 2: link the VPC with the private hosted zone in Account 1 by setting the association authorization
- Delete the association authorization after the association is established
- No VPC peering required
- Assume Account 1 has the private zone dns configured
- Option 2 (scalable):
- In Resource Access Manager (RAM), set up a shared services VPC (in central AWS account). Create VPC peerings from this VPC to every other VPC in other AWS accounts. In Route 53, create a private hosted zone and link it with the shared services VPC. Manage all domains in this zone. Programmatically associate other VPCs (from other accounts) with this hosted zone.
- Option 1 (simple):
Geolocation vs. Geoproximity
- Geolocation: Resources serve traffic based on the geographic location of your users, meaning the location that DNS queries originate from.
- Geoproximity:
Lets Amazon Route 53 route traffic to your resources based on the geographic location of your users and your resources. You can also optionally choose to route more traffic or less to a given resource by specifying a value, known as a bias.
➡️ if a question asks to route a “certain portion” of traffic to another location, this is the geoproximity bias
A geoproximity routing policy is required to route traffic to specific regions. Note: a multivalue answer routing policy might route users to randomly other healthy regions (that may be far away from the user’s location!).
CloudFront
- Failover
- Create an origin failover by setting up an origin group with two origins. One as the primary origin and one as the secondary origin. CloudFront automatically switches when the primary origin fails. This can solve the issue of users getting occasional HTTP 504 errors.
- Using CloudFront CDN (and S3 for storage) is cheaper than global DynamoDB tables
Caches
AWS ElastiCache
- ElastiCache can significantly improve latency and throughput by allowing to
store the objects that are often read in cache. Example applications:
- read-heavy application workloads (e.g. social networking, gaming, media sharing or Q&A portals)
- compute-intensive workloads (e.g. recommendation engine)
- Redis and Memcached
- Used in combination with relational databases (!), but requires changing application logic
Other Services
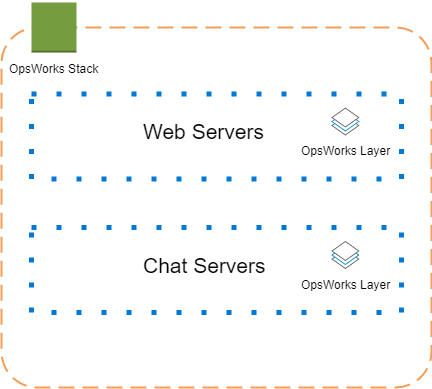
AWS OpsWorks
- Stack: one business application
- Layer: server type
- (Custom) Recipe: Ruby (!) applications that define a system’s configuration
- Cookbook: Chef playbook
Section Y: Solution Architecture
How to create a decoupled architecture for applications which make use of both on-prem and cloud resources?
- Amazon Simple Queue Service (SQS): for storing messages while they travel between services
- Amazon Simple Workflow Service (SWF): A web service that allows to coordinate work across distributed services
High Availability
- Cheap solution: Create Non-Alias Record in Route 53 with multivalue answer routing configuration. Add IP addresses of all web servers
- Common solution: Place Application Load Balancer in front of web servers. Create a new Alias Record in Route 53 which maps to DNS name of load balancer
Hub and Spoke VPC
The Transit Gateway is a highly available and scalable service to consolidate the VPC routing configuration for a region using a hub-and-spoke architecture. Each spoke VPC only needs to connect to the Transit Gateway and it gains autom. access to other connected VPCs. Inter-region peering allows Transit Gateways from different regions to peer with each other and enable VPC communication between regions. For large VPC numbers, Transit Gateways provide easier VPC-to-VPC communication management than VPC peering.
Transit Gateway enables the connection of thousands of VPCs. You can attach all hybrid connectivity (VPN, Direct Connect connections) to a single Transit Gateway. It consolidates and controls an organization’s entire routing configuration in a central place. Transit Gateway controls how traffic is routed among the connected spoke networks using route tables. This hub-and-spoke model simplifies management and reduces operational costs.
Transit Gateway is a regional resource and can connect to thousands of VPCs in the same region. It is possible to create multiple Transit Gateways per region. However, Transit Gateways in the same region cannot be peered. A maximum of three Transit Gateways can connect over a one Direct Connect Connection.
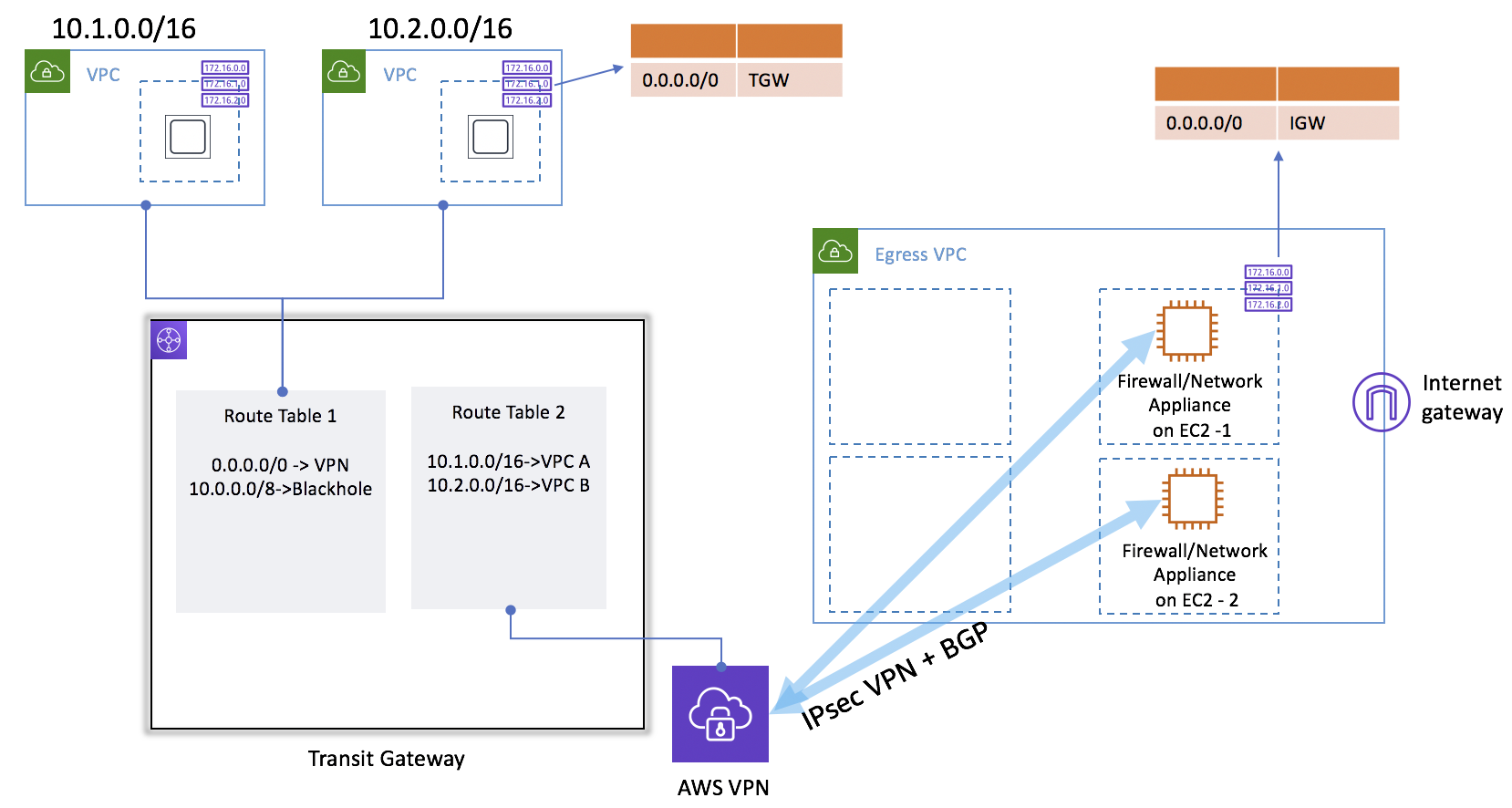
In case the egress traffic inspection product from a 3rd party doesn’t support automatic failure detection, or if horizontal scaling is needed, you can use an alternative design. With this design, there is no need to create a VPC attachment on the Transit Gateway for egress VPC. Instead, an IPsec VPN must be created from Transit Gateway to the EC2 instances. BGP is used to distribute route information.
It is expensive to deploy a NAT Gateway in every VPC, because NAT Gateways are charged by the hour. Therefore, centralizing a NAT Gateway is sensible. This can be done by creating an egress VPC in a “networking services” account. Then, all outbound traffic is routed from spoke VPCs to the NAT Gateway through Transit Gateway:
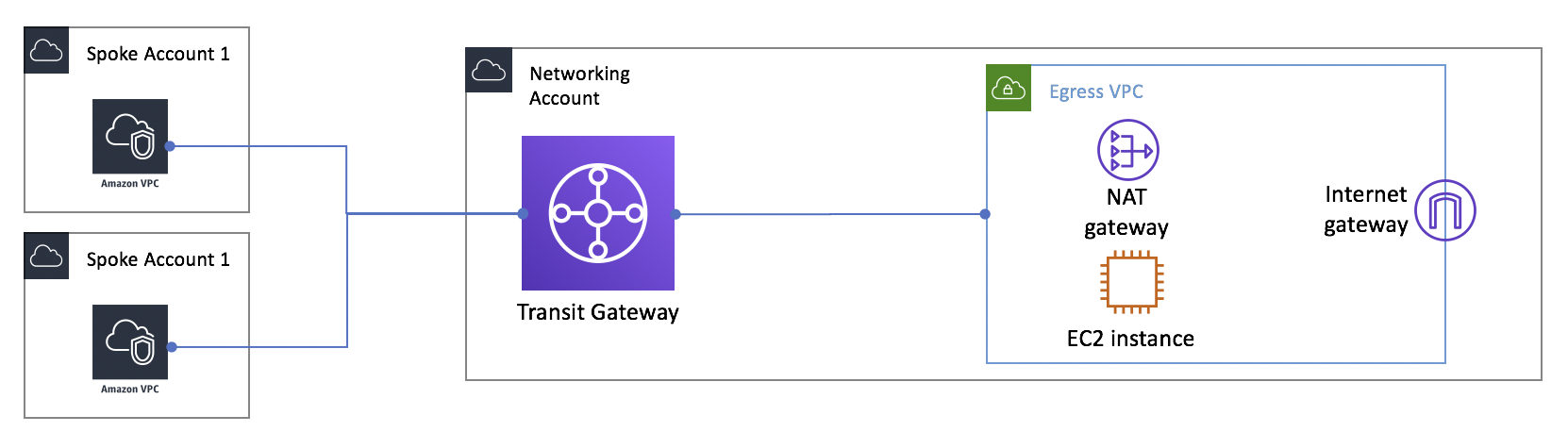
When centralizing a NAT Gateway by leveraging Transit Gateway, an extra Transit Gateway data processing charge is made.
AWS Lambda
Too Many Requests
TooManyRequestsExceptionerror can occur if too many functions run in parallels- typically, the max concurrency per function in a region is between 500-3000
- instead of beefing up Lambda resources for faster processing, change
the architecture:
- use API Gateway to stream to Kinesis
- Lambda reads in batches from Kinesis data stream
- configure function with a dead-letter queue in case function fails for any reason
CloudFront CDN
CloudFront Only Access
To ensure users can only access services through CloudFront:
- Generic service: Leverage CloudFront to add a custom header to all origin requests. Use AWS WAF to create a rule that denies all requests without this custom header. Associate the WAF rule to the ALB (ALB being an example of non OAI-compatible service)
- OAI-compatible services: Create a CloudFront user (an origin access identity (OAI)). Create an S3 bucket policy that only allows access from OAI
Programmability
An example:
- Host static content in S3 bucket
- Configure bucket as origin in CloudFront
- To serve appropriate content based a user’s device type, create a
Lambda@Edgefunction to retrieve theUser-AgentHTTP header and act accordingly
Exam Strategy
Personally, I considered the SAP exam more demanding than the SAA exam. While the SAA exam focuses purely on knowledge, the SAP exam questions dealt almost exclusively with example architectures where some problem needed to be solved or a change was required. In addition to requiring knowledge, this meant I had to mentally draw architectures in my head to understand the scenario and then solve the question.
The SAP exam has 10 more questions than the SAA exam, therefore reading fast & precise is important.
Regarding time management, I’ve deployed the same strategy as for SAA: skip long questions and do them at the end.
Also, mark unclear questions for review and process them again if there is some time left (after doing skipped questions 😉).
There can still be some distractors in the answers, most likely in the form of correct, but not quite the best answers. Try to identify them.
The exam took 3 hours, which is a long time and makes it challenging to stay concentrated. My answer to this challenge was simple: after every 10 questions, I took a micro break. During that break I closed my eyes and took 10 deep breaths. I found this to be a quite effective strategy to stay focused until the end.